Programming with LLM Agents in 2025
Download information and video details for Programming with LLM Agents in 2025
Uploader:
sentdexPublished at:
2/16/2025Views:
96.9KDescription:
Some tips and tricks for using modern LLM agents for building stuff. I am using openhands here, but you're free to take some of my advice from here and apply it to just about any of the web-based UIs or other agents...etc. OpenHands github: Neural Networks from Scratch book: Channel membership: Discord: Reddit: Support the content: Twitter: Instagram: Facebook: Twitch:
Video Transcription
What is going on everybody?
Welcome to a video on programming in 2025 using large language models, LLMs, and agents possibly.
So I see a lot of kind of critiques and questions about
agents and LLMs and coding and is it like all hype and then like some people love these things and then some people act like they're just like a giant waste of time or they don't understand like how are people using this or are they just building like really basic apps only or like what's the deal there?
And I think there's two groups of people, really three groups.
One group of people just gets it.
One group of people doesn't get it.
And then the other group doesn't want to get it.
And I can't help the latter group, but the second group I can definitely help at least maybe a little bit.
So what I'm going to use today is this thing called open hands and this is kind of an agentic layer and I will admit the term agent just sounds fancy but for the most part it is just kind of like a almost a for loop some if statements and some fancy prompting and boom you have an agent.
But done in the right way, it can make your life much, much easier.
And there's also Cursor.
The reason I'm not going to use Cursor here in this video is you have to pay for Cursor.
It's like 20 bucks a month.
And I am a little annoyed that everything is like 20 bucks a month.
But for the most part, all these things are like massive amplifications of my actual output.
So I do think it's worth it, but just because I don't really want to keep showing everything that's super expensive, or I just want to show that you don't have to pay money for like any of this stuff.
You can even use open hands with closed source, or I'm sorry, with an open source open weights model.
It doesn't have to be with a closed source model.
But you can also do a lot of things I'm going to be talking about today with something like Clod or even ChatGPT, the actual UI.
As you can see here, I even used ChatGPT because I was really struggling with what are my various options for actually loading that DeepSeq model.
I started off thinking I was going to load FP8 on a CPU.
So that's where I came from.
I never run models on the CPU.
So anyways...
Okay, so anyways, you can follow along with a lot of the tactics that I'm going to use today are similar across everything.
You don't even have to use an agent, but if you are going to use an agent, I do like open hands.
I do like cursor.
Cursor has their little, what is it, composer agent or whatever.
You can use that too.
You just have to, I think there's like a free trial and then you have to pay for it.
So anyways, keep that in mind.
I do think this is pretty cool.
You can install it essentially with two commands, run this and then run this.
And again, that's what I'm going to use.
But again, also, hopefully...
I haven't done many videos lately because I feel like there's nothing that is...
Nothing is sticking these days.
Within a week or two, everything that you just talked about is outdated.
So that's probably going to happen today.
But these principles are principles that I've been using with coding with LLMs now for...
at least a little bit.
So anyways, so I'm running that second command or actually did I already?
No, no, no.
Yeah, so I'm running that second command and I'll just open it in a browser.
And then boom, you're in open hands.
Now, I think if it's the first time you're loading it, you do have to set up an API key.
I'm using Anthropic.
I already uploaded my key.
But you can use basically all of these.
And then I'm not actually sure if... Like, I'm pretty sure you can load your own.
You can set up something with llama.cpp, set up your own little private API with that, and then you could run it off that.
So you don't have to pay a penny if you don't want to.
But I like CloudSonic 3.5 right now as my coding model, although that varies from time to time.
I swear that model gets really dumb.
I think it's just they change the number of concurrence per GPU.
That's my best guess is why it gets crappy.
But so anyways, to start, you can upload a zip and the zip works.
I wish you could upload single files.
For some reason, that does not work.
So usually my opening statement, at least to this agent, is one moment I will upload.
So well, actually, I'm just going to upload a file.
So I just open with that.
And again, every agent is going to be a little different.
So there's some little quirks that are just super specific to what I'm doing right here, but not always.
So and also let's just move.
I'm going to move my little head up here.
As for the ultra-patriotic background, I am changing where I'm putting the camera in this space, mostly because actually the old direction is filled with a bunch of toddler stuff.
So I like this backdrop a little better.
And actually, these are all like family heirloom things.
The swords on the top and bottom are from the Korean War.
Those are from the Captain XO.
And then that...
I don't know if katana, I don't think a katana is the right word.
It's a sword.
I don't think it's a katana.
I forgot, I don't know what the word is.
But that's from, it's like a captured Korean sword.
And then the bayonet is from the Civil War.
So slightly different era there.
But anyways, and then a commission flag.
Anyways, continuing on.
Let's see.
Upload.
So we need to upload our files.
So for upload and then sometimes download, at least for me, open hands used to the download always worked.
And then lately the download does not work.
so like whenever you're all done you can usually click this button and then download all the files but for some reason that has not been successful for me lately but no matter what you do first of all there's there's a million ways like you're using you just keep in mind you're using an agent you can do whatever you want don't let yourself be like contained in like a little box
So in this case, you could just open VS Code in the browser, and then now this, yes, I trust myself, you can upload and download files right here.
And what if, for example, you don't want to download all those individual files?
you come over to the agent and you tell it, zip up the files.
And then you come over here and you just download that one single zip, okay?
So start thinking in those terms.
Now for me, I am going to just upload Shakespeare.txt here.
And so I'm just gonna slap that in here.
Now, no matter what problem I do here, there's going to be people who are like,
Oh, you just solved like that.
Again, you just started from nothing.
You just worked on like a simple R&D project.
Agents don't work for a large code base.
That's all a lie.
It works for large code bases.
I'm not going to show you a giant large code base.
I also, this will be the third time I'm recording this video.
Hopefully I can actually get it condensed into one video.
And the other ones were like,
three plus hours of recording just simply because that's how long a big project takes.
And really, if I was doing it by hand, it would take me weeks, like weeks to do big projects.
So anyways, this is, I'm going to try to keep this really simple and still show all my tips and tricks, I suppose, for working with agents, but also hopefully be able to show you
why these things are so powerful.
So, okay, with that in mind, let's go.
So, we have Shakespeare.txt, and now one of the actual benefits is quick R&D.
So, for example, imagine you don't like language models.
Like, we've been on this transformer schtick for so long.
Like, wouldn't it be nice if there was something else besides transformer models for either language models, but then also, in my opinion,
Before we reach like ASI, we are not going to be doing it with chatbots.
I just don't think so.
And like the base core thing, the base core element is not going to be tokens, right?
There's certainly not word tokens.
So...
What is that word?
Let's just scroll down a little bit here.
This is Trump's America, I suppose.
But anyways, what is that word?
I do need to know.
I need to know.
Do I have to like redo this video or not?
What is Shakespeare's usage of the word mean?
So I don't think...
Yeah, what's the...
Anyway, I've just got to figure out if... Claude says it's unrelated.
We're good.
We're good, guys.
Okay, so...
So I don't think that like even think about like humans, human intelligence.
Human intelligence, is it the result of language or is it the result of communication, right?
And I think language is like an emergence of communication and intelligence as opposed to being like the source, okay?
So I don't think AI in the future, like ASI type stuff.
It's not going to be from tokens, right?
Okay, so anyway, so what if we try other things?
Okay, let's imagine that's the pretext of our new project here, now that we're 10 minutes into this video that I really don't want to be three hours.
So we've uploaded our Shakespeare.txt.
We're going to use this as training data.
And let's say we want to use an evolutionary algorithm to train on Shakespeare.txt.
Now,
To begin, we could do quite a few things.
So first of all, on Shakespeare.txt, we could say, hey, I want to eventually train a language model on the Shakespeare.txt file I uploaded.
I would like to have the input be an encoded, let's say 15 characters, 15 characters and the output be an encoded three characters.
I am not positive on the encoding.
But I think it would be cool to make that a bit style of encoding.
Like, make each character the bit representation of that character.
Okay, something like that.
Hey, bro.
Something like that would be really cool, right?
Like a language model that's actually built from bits.
Like, that would be...
Darn near a holy grail, I think.
There's all kinds of problems that are going to likely arise from doing this bit encoding, and I promise we are not going to solve it in this video.
This is a very complex problem.
But I just kind of want to show some of my usual things of working with these agents and large language models.
So one of the things is you would never approach
the agent and ask it to do the whole thing in one prompt, right?
That's way too big.
You would not approach that problem.
Now, maybe in the future when we actually have ASI, we could ask, you know, hey, hey, this is what I want.
Make it happen.
And maybe that will work.
But today, you can't do that.
Just like regular programmers, you can't do it that way.
You have to break it down into little sub-problems and then solve the sub-problem one step at a time.
So I'm just informing it, hey, this is what I'm headed towards, right?
And I think I want to encode it this way.
So I think the first step we should do is take that text file and create some training data from it in this way.
Let's create a Python file that first loads this text file and encodes the characters to bits and then creates the input 15 characters to output 3 characters but encoded into bits.
Can you do that?
OK, so hopefully we'll start off there sometimes like this agent will like write the code, but it won't make a file.
I think it's going to make a file here.
We'll see what happens.
And we want to do three characters instead of one character, because I think a lot of times we'll end up on spaces and stuff like that.
Also, I think if we do only one character, the model will vary, especially with an evolutionary or RL-based kind of algorithm.
But many algorithms would learn to predict the most common letter and then probably get stuck in that kind of a local minimum, basically.
And we don't want that.
So we're waiting on this thing to hurry up and code.
So yeah, it calls it pre-processed.
That's good.
I mean, that's what it should be called.
And we're just kind of waiting for it.
So one of the other cool things about agents is, you know, some people say that it takes you, it takes much longer to produce code than if you just like wrote it yourself.
And sometimes that's true.
Like sometimes there's like a really easy solution and like you think that you can get the AI to do it for you, but it would just be quicker if you just did it.
Oh, that's cool.
So it saved it as a NumPy.
So remove, so how many training samples from the first thousand characters?
I don't know if I want that because it is likely a sliding window, but I'm not really sure if I like it being only 1,000.
Let me just see if the down, this historically, well, historically this has worked, but lately it has not worked.
So I just want to see if it works.
it is not going to work today.
I don't know why that is.
Oh no, I forgot.
This is like when this breaks, you have to like refresh.
It's like super annoying.
But anyways, we'll discuss that momentarily.
So here's the next tip and trick that I like to do.
So it's done this already.
And so as you can see, we already have, we have that text file.
We've got these NumPy files and then we've got the Python file.
And as you continue to increase the size of this codebase, you will wind up with more and more issues along the way.
So what I like to do is, could you also create a, in this case we'll call it a readme.md file, that summarizes our current goals and objectives, the things we've done so far, the files in the codebase,
Actually, we'll call the files in the workspace and a bit of a to-do, of a to-do.
Beyond that, please try to keep this file up to date.
The reason why I want to do that is as I discuss, as we talk in this little chat box here, the context gets longer and longer and longer and longer, and eventually it gets a little unruly.
In general, I find the correct number of steps to take.
Now, it depends on the context per step, but
In general, by the time I reach like 200 steps, I find it's best to go ahead and just reset everything.
And so in order to do that, you need to at least have kind of like this running sort of summary of what's going on, what you're working on, and all that to like come back from.
So you'll either download all the files if that actually works.
Again, historically that has worked.
And just for the record, this is like right now as I record the version 0.23.
I feel like the version updates like once a week or something like that.
It's pretty frequent.
So hopefully at some point that'll be fixed.
So we'll see.
And honestly, it's been a lot of fun using this one because it updates like so fast and there's like little things that hopefully we'll get to see some of that in this recording that I'll kind of point out.
But like little behaviors that you see come through that clearly like the prompting has changed and you're like, oh, that's so cool.
So anyway, so now we have this readme file.
So again, we can come over here and we can kind of just see what it's done so far.
So it just populates this with some useful information that if we want to start over the context, the first thing you tell the agent when you start a new chat is please check the readme.md file to understand what we're doing.
And right before you reset, you'll tell it, you'll just make sure that it has updated the readme.md.
You should double check it and you can make any modifications that you want or whatever.
But I find that to be a really great way to keep context down, keep everything kind of flowing pretty good, but then, yeah, not have this like giant, because like sometimes like that giant context actually makes the model worse.
So, whether or not you care about paying for those tokens, it's also just like trying to keep it focused.
So, anyways, coming back to where we're working.
Okay, so we got the README file.
Very good.
And we created some samples.
Now, we want to make...
There's all kinds of stuff you could do.
I like evolutionary algorithms.
I just think they're really cool.
But in the case of binary, it could be an evolutionary algorithm.
It could be an RNN, right?
It could be all kinds of things.
Something new is coming, for sure.
It won't always be transformers.
So anyways, let's say you want to try an evolutionary-based algorithm.
Okay, so I'd like to try an evolutionary-based algorithm to start on this data.
What do you think?
And then also, let's check this pre-process.
So what I will say is...
I think that we probably would want to have more than a thousand samples, most likely.
But then also, one of the things I want to point out is a lot of times when I'm working with these agents, the agent will have produced thousands of lines of code for me, and
I won't have even seen it.
Like, I won't even look at it.
That's where things are lately.
And I just think that's pretty crazy.
So, like, I get a little bit of benefit having been a programmer in a past life that, like, I know it's possible.
I know it's not possible.
Like, when I'm asking the model here to use an evolutionary-based algorithm, I could tell it, hey, use the neat library because that's a really good library to get things going.
Okay, this is just a sample.
I'm not sure what it's doing right now.
Is it actually running something?
What are you doing?
So it's pre-processed, but then it's not actually... Oh, so it is building something.
I just don't see it for some reason yet.
Here's that file.
So I get a benefit because I know what is possible or what exists.
But again, I do think that we're kind of at the point now where we could... You could probably program...
without being a programmer at all.
You could ask an agent like this to do things and just report the results.
Okay, so coming back here, an evolutionary is an interesting approach, blah, blah, blah.
Update the README.
Look at that, being a good little agent.
Input, 120 bits.
Hidden layer, 64.
So I do think that we probably need two, minimum two hidden layers.
I think that that has been very well documented that you have to have at least two hidden layers.
So we'll go ahead and add a hidden, I think we'll start with two hidden layers, minimum.
Genetic operations, blah, blah, blah.
Mutation, flips bits with a given probability.
Combines two parents, selection.
I do think we want some sort of mutation and evolution that adds layers adds nodes removes nodes adds connections all that kind of stuff and
fitness is slightly above modelism, blah, blah, blah, architectural changes, blah, blah, blah.
Okay, so again, I do benefit from having been like a programmer working on these things, literally writing the book on neural networks.
You're gonna need a second hidden layer.
So let's go ahead and let's make the default starting point have two hidden layers.
um well how many was it 64 64 that's just that's well 64 is fine we'll keep six the problem is that you don't really even need probably 64. uh two hidden layers um two hidden layers uh 32 nodes we'll just start there uh to start um during evolution we should allow for mutation to add nodes
Add nodes, add nodes, connections or remove as well as add new layers.
Adding new layers should be relatively rare but possible.
I'm trying to think if there's anything else I want to change.
So coming over here as well, let's see.
So, I mean, we did, we improved general fitness.
We did 50 generations.
We don't have very much data.
And then it's also important to recognize the average fitness.
I think until average fitness goes up, that means no improvement, really.
I'm not sure about 50%.
I guess 50% because it's a zero or a one.
I guess that's how that's doing the calculation.
And then the actual predictions, I mean, most of these are like special characters.
I'm going to call that emergence.
So, I'm ready to raise seven trillion dollars on, hey, I just created a, you know, people always say that language models can only produce what they were trained on, like they only know what they were trained on.
Boom, here's some evidence.
I got a model right here.
It's emerging on a new language.
$7 trillion.
Okay, so one of the other benefits of these agents is, like, I'm doing this and talking to you.
Again, I'm not really writing code.
I'm writing English, and that's about it.
In reality, when I'm working, even if I just was trying to solve this one problem, I would have four of these up at any given time, five maybe.
And if I'm not working on just this one problem, maybe I'm working on multiple problems, I'm going to have many things up all at once.
So even if the agent itself is barely faster than you are,
if you're just on that one agent.
The difference is while this agent is doing this, I could be off instructing a different agent to do something else.
At a minimum, this thing, it speeds me up.
I feel like even one agent, I'm usually about 10x my speed.
But I can use five agents at a time.
So I'm like, 50x.
I mean, it's crazy.
The amount of leverage that you get when you're using something like Agents is...
It's absolutely staggering.
Okay, so I'll modify the evolutionary model, blah, blah, blah.
Dynamic architecture, mutation types, 80 chance...
Hey, it improved to 50%, but I think at, I'm not sure best fitness really matters.
I feel like average fitness has to, you have to raise up the average fitness, otherwise you probably haven't.
Training, increased, so what is the population size?
Possible improvements we could try.
A fitness function.
Okay, so I actually...
I mean, it was a joke earlier, but I actually don't think you want to get rid of this.
You might want to.
It might actually make it better, but I don't want to do that.
It's more fun not to do that.
Weight different bit positions differently.
I mean, that is the other thing.
So, one of the common things with...
So like with 8-bit representations, I want to say the 128 comes from the fact that you have, even though it's represented in 8 bits, the 0th bit is always going to be a 0.
Or at least almost always.
I think there might be some scenarios.
So I'm going to comment below if there's what scenarios that the 0th bit would be a 1.
but you can almost guarantee success, which is why it's unfortunate that we're still average fitness 50%.
Like we should do a little better because you could always predict that zeroth every eighth bit.
So like here, zero, one, two, three, four, five, six, seven, zero, one, two, three, four, five, six, seven, zero.
Like it should always be a zero.
So it's shocking it hasn't quite figured that one out yet, but that's okay.
Okay, weight, different business.
Okay, first off, first off, since we're rep, I don't even, I don't know if I, I feel like that could, that would like confuse the agent potentially.
So I don't even know if I want to touch that.
Consider sequence level patterns.
I don't think, I don't know if I would want to do that.
It feels too token-y like architecture.
Start with larger layers.
I'm not sure.
Why would you need to start with larger layers if it's 8-bit representation?
But you do have, okay, fine.
We'll start, okay, fine.
Okay, fine.
Let's go with larger layers, 64 each to start.
Remember though, we can always add more neurons.
I'd rather start small and grow rapidly than start giant.
Okay.
What is our current... Increase the... What is the population size?
I don't even know.
I have no idea.
It's not my code.
Let's see if we... 100.
I feel like 100 is a pretty good starting population, but... Increase the population size to whatever you think is best.
Yeah, I don't really know.
I feel like 100 is actually pretty good because I also think the population size, I don't know in this code if the population size will ever grow.
One moment please while I check something on my phone.
Hmm.
Okay.
64, that's five.
200 population, dynamic, bit flip.
I think bit flip is a potential issue that starts to suggest to me that maybe our activation functions are dynamic.
I hate that it does this too, but there's something else we can do for that as well.
So as it runs... Oh, it's running right now.
Yes?
Yes?
dynamic evolutionary model.
Wait, where is the activation?
Where is our activation function?
Wow, I can't even find it.
Add node, remove node, add layer.
Am I blind?
I'll just ask the model.
What are the activation functions for these layers?
Started here, improved to here.
Yeah, it's probably not.
And I bet the average was still, yeah, too close to 50%.
Weighting bits by position.
I don't even know what MSB or LSB stands for.
I don't want to... Should we?
We could probably improve immediately if we just made that change.
Skip connections.
Yes, add skip connections.
Yes, add skip connections.
Yes, add...
Attention with... Let's try to add some attention.
It is all you need.
Damn it.
We're just going to wind up creating a transformer probably.
But okay.
Evolution strategy.
Add speciation.
Like in neat.
Island model.
I don't know what island model... Let's also improve...
Oh, man.
The calculation is probably adjusted from this point, but... Also, let's try to keep the Py files in the workspace somewhat clean.
Please...
put previous evolutionary scripts that we're no longer using into a folder called prev.
So hopefully it'll do like multiple things here.
Yeah.
So there is no activation function.
So that's your problem.
It's really an XOR.
Exactly.
With new activation functions, binary sigmoid, binary tanh.
I think a sigmoid would be good because then we would likely see much more training.
Binary and binary.
OK, that's fine.
I don't mind tanh and sigmoid.
Output layer.
I'm predicting all ones.
Oh my god.
Oh, there you go.
So you do have scenarios where you could actually start with a 1 instead of a 0.
Okay.
Scale the weights to prevent saturation.
Add weight initialization scaling.
Add a biased term to help with activation.
Improve the fitness function to consider partial matches.
Sure.
Let's do all of those.
Probably.
Okay.
Oh, look at him.
He's still erupting.
Usually it forgets to do what you asked it with respect to the readme file.
So I'm pretty impressed that he's remembering to do that.
All right, let's see if this actually... Did you put anything in there?
So wait, is it putting...
Hold on.
No, just evolutionary transformer.
So why is this...
I don't know why these two...
Unless it's using it.
It doesn't look like it is.
Okay, this might be the new...
This might be an example.
I think it's actually probably still running.
Let's see.
Hard to say.
This is all probably just the spyware on my computer running.
Let's see.
So let's check in on the current status.
Yeah, okay.
So that's what I thought would happen.
So this was, I think, new as in 0.22 or 0.23, but it used to be the case that if you had any command that would take longer than two minutes, you just couldn't run it in open hands because it would just time out.
It would just say, oh, this is taking too long, and just give up.
Whereas now it just it like Just sends it it leaves it running and then just sends this empty command and it should give you a result But it's possible that maybe this is not printing as it's going So we'll see if it gives it let's interrupt the current process to add some progress indicator.
Yeah, I literally read my mind
So again, we're sitting here.
This is taking a while.
I'm looking at the timer on the recorder, 34 minutes.
And again, I just want to say, while it's doing this, I would be in a different window doing something else entirely.
I'm not going to sit here and keep staring at this.
And there's so many things that are very common.
So for example, let's check in on the current status.
There's no information?
Oh, right.
You have to basically, all your scripts should have tons of debugging happening in the console.
And if not in the console, it should output to like a JSON file, something like that.
So if it takes a really long time, like in the case of like,
benchmark scripts for language models, for example.
It might take a while to run and get the inference for those benchmarks.
And then if you want to perform analysis, or you want to work on the logic of extracting answers from the inference, rather than re-running over and over and over, just output to a JSON, and then you can iterate over that JSON.
But again, these are all...
This is all stuff that you should have been doing when you were programming as well.
We're still in an era where you still kind of have to be the engineer, and you still kind of have to think about how to break things down.
like a big problem break that down into smaller problem and chunks that you can kind of solve and use things like debugging and all that and for more challenging things generally if you can come up with like a like a test case where you would know if it worked if it passes these tests or you'd be very confident at least you can come up with those tests and then tell it this is the test you would save it to like a file even and say hey this is the test case just keep iterating until you can solve these test cases
And eventually it will either, you know, expend a ton of money or solve the test cases and you'll be good.
So like there's lots of like little ways that you still have to like be a programmer to some extent or an engineer to some extent.
But everything is just so much easier nowadays.
And then let me see here.
I will say like at least Claude if you're seeing like I apologize or if you see like the oh now I see what the problem is if you start seeing that stuff a lot just you got to clean up start over because it'll be stuck in a loop forever as soon as you start seeing messages like that like definitely start the context over all that it's it's a lost cause at that point okay so now the fitness evaluation is taking quite long so for example
What was my memory up to last time?
I don't remember.
Let's first see how things are progressing, even if it's slow, before we go making changes.
I think we'd like to see at least a few generations.
I mean, we're definitely something's happening because we're using massive amounts of memory.
Not quite sure what or why, but we can address that at a later date.
I'm just I just really want to see number go up.
Like, how hard is that to show me number go up?
Let's go ahead and break that, then use NumPy's
Vectorization plus, let's use some parallelization.
I have 64 total cores.
Let's reserve 12 for me.
So use 52 to process.
Yeah, you start seeing stuff like this, you should be on red alert, at least with Claude.
Ah, anything like that?
No, no, no, no.
You got to be careful.
Whoa.
Look at it go.
Oh, for a split second.
It must have hit another error probably.
That was awesome looking for a moment.
Ah, I see the problem.
Ah, now I know what to do.
Ah, I see.
Ah.
There you go.
As soon as you, if you have too many ahs happening all at once, things are not looking good.
We'll see though.
We'll see.
We'll see.
It's a red flag though.
It's a red flag.
Watch closely.
Dang, look at them go.
Did I or did I not say 52?
I think it's violating my request.
It's probably going to screw up my video.
Okay, we are, check the timer on the video, 57 minutes, 57 and a half minutes away.
And I have done no coding.
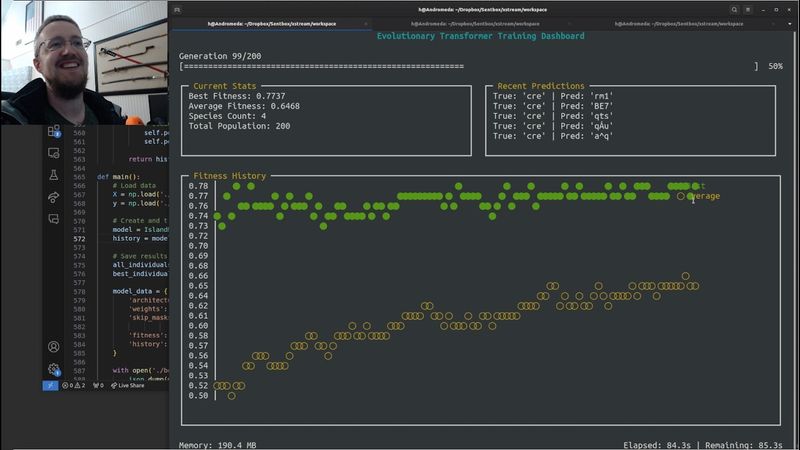
We have reached the point of, basically here we got a best fitness up to 76%.
Reached that in generation 47.
I think we only did 50.
And actually it really probably was, it did 50, but it starts at zero.
So really it only had two more generations.
So it sounds like it was continuing to improve as time went on.
Started to predict valid ASCII characters.
Final predictions show learning of character patterns.
I'm not really positive that I would necessarily agree with that, but that's what it says.
Areas for improvement, more sophisticated fitness function, maybe.
It seems like things are getting better, but if we're already at 0.76 and these are the predictions that we're getting,
My guess is potentially this is more like a local minima type scenario, but we'll get there.
Okay, so probably the last thing I would do here is show you guys, well, two things.
One, again, I don't know what step we're at, but I don't think we're near enough to reset...
Yeah, we're only at step 85.
But again, if you did need to reset context for any reason because this download files is not working, you literally just ask the model, hey, could you please zip this entire workspace into a workspace.zip file for me?
Thanks.
And it will do that.
It probably doesn't have zip installed, but it will just install zip and put it in a workspace.
And then from here, you can do all kinds of stuff and like stuff that I would just never personally do.
Like you just would never take the time to really make it really nice.
So for examples, like visualizations, dashboards, stuff like that, like as this trains, one of the other things that you could ask is, hey, instead of like a tensor board necessarily that just shows the stuff that tensor board can show, you could tell it like,
Hey, show me the best fitness, show me a best fitness graph over time as it trains, like create like some sort of dashboard for this.
And then also things like show me some examples, like every generation.
So show me some of the best final prediction examples, stuff like that.
And you can kind of keep going with that.
But anyway, for doing stuff like that, for like dashboards and all that, it's really, really powerful.
So anyways, this is like a perfect stopping point.
It was an hour in.
Again, I did almost no coding.
A lot of that I was just like looking at something else, doing something else, or talking to you on camera, or like explaining something.
But really the actual input required of me was minimal.
to get to this point.
Now, again, we did not solve, we didn't make a new breakthrough in new language models or anything like that, or we didn't make ASI today.
But the point is you can use this to do, like if I'm not recording a video, again, I'm doing like five of these at any one time to try to solve certain different problems.
So especially if you're an R&D or something like that, it is much faster, but it doesn't have to be R&D.
It can literally be like I use this with my work for benchmarking large language models.
It makes it so much easier to like quickly implement a benchmark like any benchmark.
There's always like all these like brand new benchmarks.
Everyone does them in different ways.
Everything has its own little quirks and features and every model is a little different and
It's just kind of a nightmare implementing models on benchmarks, for example.
But doing it with language models, it's like so easy.
It's so fast, like when you're using something like an agent.
So anyways, I definitely encourage everybody to try these things out.
Try out open hands, use the cursor agent, even just using the chat, you know, the web UIs.
All these things are extremely powerful.
And if you're not using them, you're missing out.
If you're refusing to use them, you're going to be replaced, probably.
So anyways, that's all for now.
If you have questions, comments, concerns, suggestions, something else I should look at, let me know in the comments below.
If you're interested in learning about how neural networks work, like at a deep level, check out the Neural Networks from Scratch book at nnfs.io.
Otherwise, I will see you guys anywhere from a few days to a couple of years.
Till next time.
Okay, bonus points.
I did ask it to do something and then I left and I think it actually maybe worked.
So basically I just asked it to save like best fitness and like all the fitnesses to like a JSON and then we could display it in a live dashboard as it trains and then maybe view progress over time or something.
So it looks like it actually did that and then I just asked it, hey, will you zip everything up into a workspace.zip because I was having a problem like doing the download all files thing.
So it did that, made me a little zip file.
Okay, so coming over here, we will extract...
come into the workspace and, um, what were the two files?
I already forgot.
We want to run a training dashboard, um, for the live visualization and then oops, uh, Python training dashboard.
Um, okay.
We'll see.
Uh, and then finally, uh, what was the other thing?
parallel evolutionary transformer.py pull that up and actually that needs to be uh python python parallel evolutionary transformer.py cool um oh it's uh it's acting like it's a local hold on let me fix that
Okay, so in these two files, this is what we want to do.
We want to replace workspace with like nothing.
Now we could ask the model, like you could pass this error to the model, but I don't have time for this.
So I'm going to do that, save, come over here, and then basically, yeah, do the same thing.
Just get rid of all, wait, did it not?
There we go.
Okay, save.
So then coming back over to here one more time.
Okay, so things are training.
Ooh, things are laggy as heck.
And then we'll come over here.
I don't really see anything yet.
Island one.
Oh my gosh, it's murdering.
Hold on.
Okay, I just can't help myself.
I have to go.
But this is just way too addicting.
First of all, what the heck?
This is not what I was expecting for a dashboard.
But this is like the coolest implementation of a dashboard that I could ever have expected.
I would never even ask for something like this.
It does appear that the trend is going up.
And then, yeah, what I want for the fitness history is to be both best fitness, but also the average fitness.
I think that would be cool to track as time goes on.
Okay, that's easy.
And then, okay, that's fine.
So hopefully it'll do all this.
We'll ask it to zip it one more time and then we'll run it.
And then that will be the end.
I just can't help myself.
This is the coolest visualization.
I would never have made this visualization.
This is just so cool.
I just, I have to see this.
Very good.
Okay, great.
Work space as up to contain all of this.
Awesome.
What is this about?
Oh, that's just a historical.
Okay.
Okay.
So then we'll come over here and I'm going to grab this.
Training dashboard, run that and then run this.
And finally, we will also pull up each top, make sure it's doing what we said to do, please.
Oh, the dashboard's already running.
OK, so run that.
Oh, this is this must be the average.
Yeah, it says so.
Oh my gosh.
Is this not just the cutest thing in the freaking world?
Oh my god.
And it appears to be honoring our request.
That's cool.
Oh my god.
I'm nerding out over this.
This is so cool.
Oh my God, this is the best dashboard I've ever seen in my life.
Oh my goodness.
This is so cool.
I can't get over this dashboard.
That is so, so cool.
So probably I would do maybe more generations to see if this keeps going up.
But I'm having way too much fun.
That is just so cool.
Let's see.
Parallel evolutionary transformer.
Somewhere in here we got to be able to pick.
Wait, where did it?
Okay, num cores.
That's fine.
My dog is like licking the floor, making nasty noises for us.
Where is this?
What was it?
50 generations?
50?
Maybe it's just islands.
Oh, generation.
Here we go.
Can we do that?
So island size 50, generations 50.
Let's do 200.
Save that.
And then I wonder, can I just restart?
I have no idea.
I have no idea.
This is not my code.
It looks like we can.
Dude, I can't get over this chart.
This is the coolest thing.
I wonder if we're going to ruin the chart, though, because in the past it looked like if this is 15 out of 200, I wonder what happens to our chart.
We're going to find out.
Come on, buddy.
Let's go outside.
Dude, I love this.
This is just so fun.
This is so fun.
I would never have made a dashboard look like this.
Here, let me, let's see here.
I'm gonna move this over a little bit and then maybe do like that, fit my face in there.
Could also just get rid of it.
Yeah, isn't that awesome?
Oh my goodness.
I love this.
I just love this shit.
Okay, so I am kind of curious what's going to happen because we're going to run out of space here and I'm guessing this will not handle for that.
But I mean, this is, we are off to the, this was, this is like the, this is way better than I thought it was ever going to be on this video.
I'm so excited for this kind of a visualization.
That is so cool.
I hope you guys are enjoying this visualization as much as I am.
Look at the covering over this.
Oh my goodness.
This is just like the coolest way, dude.
I need to learn more about how is it doing that.
Like, I need all my visualizations to be in the console from now on.
That is so cool.
Is it moving?
It is moving.
Oh, man.
Oh, my God.
I just had no idea this was even an option.
See, this is a perfect example of like, yeah, in some respects, it's useful to be a programmer because you know like what's possible, what's not possible.
But then in some respects, it's like, man, I didn't even know this was possible.
I had no idea.
This is so cool.
This is so cool.
I'm dying.
It's all with curses.
Oh my goodness.
this is so this is mind-blowing to me i wish we had i wish we had the full history because it looks better because like now the gains are slowing down um but dang dude that's so cool that is so cool i hope you guys are loving this as much as i am i to be honest i don't even care if you don't uh that is that is super cool um
It is predicting slightly better, like it's getting closer and closer.
We have a lot of work to do still.
But like I said, we were never going to solve this.
We were never going to solve that.
But this is way better than I thought it was ever going to be.
So that is super cool.
Okay, now for real, I am going to cut it here.
I could spend, oh my God, I could spend hours at this.
I love this visualization.
That is so cool.
Wow.
Yeah, so anyways, I'm going to stop here.
Questions, comments, concerns, suggestions, whatever, feel free to leave them below.
Maybe I will have an update on this because I definitely have to keep trucking along.
And I love this dashboard.
I'm going to make everything...
I think I had been wanting to look into curses for some time now.
I just never had the opportunity.
And again, this is a perfect example.
I would never have made this.
Not in a million years.
But the joy that has been brought to me by my agent making this for me is immense.
Immense.
Wow.
Wow.
Okay.
Yeah, that's all.
That's all for now.
I will see you guys in, I don't know, another few days, few months, couple years.
Who knows?
Anyway, till next time.
Use some agents.
I just couldn't help myself.
I'm back with some more bonus content.
I need to know two things.
I need to know, first of all, rather than having the sliding window, can we make it such that it has all of the history so we can see it more like long, large scale?
And then also I must know, can we make this like a line?
Now I know that this is just curses, like it's not a graphing library,
but I really need to see lines.
Like, I need to know, is this doable?
So that's what I'm going to do.
First, I'm just going to say, looking really good, could we change from a scatter plot to a line graph for both of these metrics by chance?
I think that would look better.
Also, could we add values to the X-axis?
X-axis generation number.
And then finally, what was the other thing?
Finally, could we show all the steps rather than just a sort of sliding window?
So let's code for 200 generations.
And when we get to 200, I want to be able to see from the beginning to end all in the chart.
Makes sense.
All right, let's see.
Let's see if this can do it.
I will be super excited if so.
This has changed...
So much for me.
I don't know if we can label the x-axis.
That would be crazy if we can.
This is just so cool.
I'm a real sucker for stuff like this.
I'm just making colors in the UI of some sort of console stuff.
That just tickles me.
But this is something else, especially when it had a legend and everything.
Come on, man.
That is crazy.
I mean, it's just crazy.
We'll see if it makes these modifications.
I feel like the line graph is probably somewhat difficult.
Coding this is probably easy, but making it be lines I feel like would be pretty hard without...
I don't even know.
I mean, I know you could do it, but you would almost need some sort of graphing package or something.
I don't know.
But even this, this is really cool.
I'm tripping.
I'm going to need it to always do this for me from now on.
I don't want a web-based UI anymore.
I need this.
Also, I apologize.
My eyes are dry as heck.
We're having some crazy weather right now, and it's getting very dry.
We have like this massive cold front coming in.
Okay, so cool.
So I think it's done.
Great.
Let's go ahead and zip all that up, please, into workspace.zip.
Very good, very good, very good.
Okay, that makes sense.
Okay, that'll make sense.
Very good.
I mean, let's just see if it works.
Oops, what happened here?
Oh, okay.
Anyway.
All right.
Wish us luck, everybody.
Okay.
I'm not sure what I'm seeing here.
I mean, that's not terrible.
I was really hoping to like have slashes be used, like to notch up, use a slash.
I think that would have been pretty cool.
And then I'm not sure what's happening down here because it like was modifying that.
That's kind of odd.
Maybe we'll go back to the scatters.
I'm not really sure.
It's just so cool.
I just can't stop myself from tinkering with this.
And I don't know, it's what makes it so much fun.
It gets you straight to the fun of programming.
And again, I think it probably varies by who and why.
Why did you learn to program?
Do you like to program or do you just like to build stuff?
And like, I just wanna build stuff.
and uh this just makes it really fun to do so because now okay like i just i'm trying to answer some questions you know so like this helps me to first of all see okay i can actually see like okay there's a little bit more of a trend going on here um and now i'm starting to wonder i mean this is running really fast as a parallel process now too and so like if we check uh h top real quick
Yeah, we got plenty of cores to dedicate to the cause.
So we could go longer, we could add a much even bigger population, we could add way more exploration, all that.
So I think that's probably what I would likely do next.
Please don't expect more bonus content, though, because I have to stop at some point.
I just have to.
But, I mean, look at this curve.
I mean, dang.
It's begging to continue onward, honestly.
I've got to do more than 200, apparently.
Oh, man.
This is so addicting.
Anyway, yeah.
Agents are awesome.
Yeah, that's just so cool.
I think we probably need to put the...
The legend, like down in the bottom right, you know, like that's probably a better spot for it.
Or like outside the graph a little bit or something.
Or even like up here, like in this little title.
But overall, yeah, that's pretty cool.
There's a very clear trend here.
I would keep going.
I would look possibly even further into what is fitness and all that.
Make sure that's actually still logical.
We probably want more than four species.
I don't know if that's like the island concept or what.
So I'd probably want to look more into that.
but again instead of like looking at the code i mean directly looking at the code you would just ask the agent um you know hey what's going on here why is it only four species oh it's because okay let's have more and like let's have more uh mutation like you you would keep going from here um but i mean right now we're actually on a pretty interesting track like these these uh predictions aren't exactly uh perfect but if i recall right we did not reward for ask not or yeah we did not reward for like straight up characters like e j e all that like
The model is just learning that that's probably more likely what we're looking for.
And even that, that's cool.
I didn't think that this would get this far, to be honest with you.
So yeah, that's awesome.
That is just so cool.
And I love this curses.
Oh man, that just, that really did, that's like made my day.
So, okay.
I really should stop it here.
Otherwise this will be yet again, another like five, 10 hour video.
So anyways, that's all for now.
Bye.
Similar videos: Programming with LLM Agents in

Как изменить цветовую тему для Visual Studio Code

Как подключить CSS к HTML || How to connect CSS to HTML || CSS Full course

هوش مصنوعی فول استک یعنی این !

Навайбкодил приложение по вечерам! 50К строк за 4 месяца

Как настроить миникарту в Visual Studio Code || Visual Studio Code Tips and Tricks
